Parsing the UrbanSound8K dataset with TensorFlow

There are multiple ways of feeding data to a Neural Network. Most often, Numpy arrays and CSV/Pandas files are used. Additionally, TensorFlow offers a custom storage format, TFRecord. It's handy but not very beginner-friendly. Many datasets are readily available, such as MNIST or CIFAR. However, getting other datasets into the TFRecord format is not that hard once you've done it a few times. Here, we'll thus parse the UrbanSound8K dataset, store it in the TFRecord format, and, finally, iterate over its samples.
Dataset description
The UrbanSound8K dataset contains 8732 audio files of varying duration. At most 4 seconds long, each sample belongs to one of 10 classes. The files come pre-arranged in ten folds and are stored in WAVE format. Each file might have a different sampling rate, bit-depth, and number of channels. With ~7 GB, it's a medium-sized dataset. Thus, if you're looking for a smaller, more-accessible audio dataset, then have a look at ESC50.
Downloading and extracting
Go to its web page and click on the download link at the bottom to download the dataset. Depending on your connection, it might take a few minutes. After the download, unpack the archive. You now have two folders, audio and metadata. We only need the first one.
Within this folder, the files are pre-arranged into ten folders, fold1 to fold10. All files are named according to the following scheme:
{SOURCE_ID}-{LABEL}-{TAKE}-{SLICE}.wav
The first part is used to identify the ID of the source file, LABEL is for the class label, and TAKE and SLICE are used to distinguish between multiple samples taken from the same original file.
Parsing audio data into TFRecords
As a word beforehand, if this is your first time working with TFRecords, TensorFlow's native format for efficient data storage, or you need a refresher, have a look at this Google Colab notebook and an accompanying description here.
We do not need the metadata file because an audio sample's label is inscribed in its filename. We can thus directly start with writing the data to TFRecord files. To get this done, we first import some packages and a couple of helper functions:
Afterwards, we define a function that loads the audio from the disk. For this, we use the librosa library. Though there are alternatives, such as scipy, I found it most convenient. Furthermore, we can quickly extract the label by splitting the filename first on a "/" and then on the "-". In the end, we return the audio data, its sampling rate, the label, and the filename:
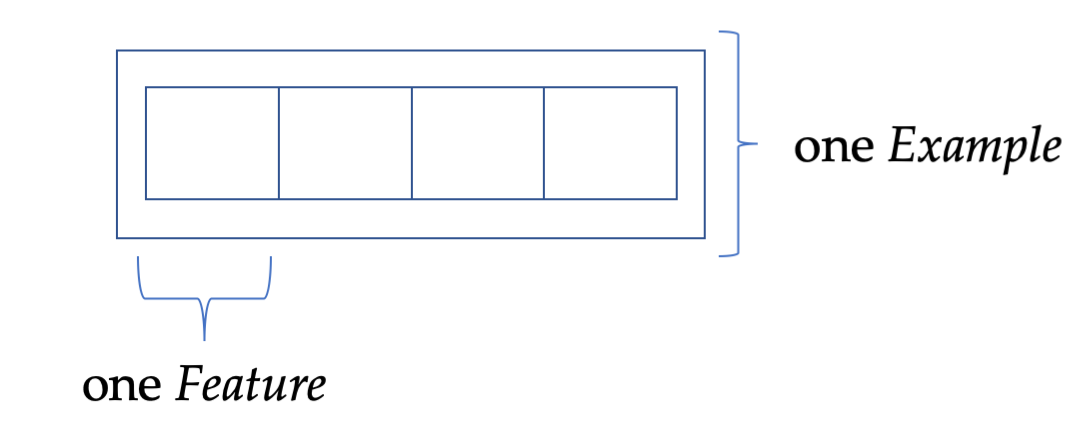
Afterwards, we define the function that makes the extracted data ready to be stored. Here, we'll use the helper function implemented previously. As I describe in my introductory, hands-on guide to the TFRecord format, these functions are used to make integers, floats, strings, and byte data ready for writing to disk. Giving the features appropriate names helps us extract them later on. Lastly, we wrap them into an Example object, like a box with some content and properties. The following image visualizes this concept:
We have two core functionalities defined: Loading the audio data from disk, and parsing it into a TFRecord-compatible format. Therefore, we can now implement the method combining both. To do this, we create a TFRecordWriter object responsible for writing the data to disk and iterate over all audio files that we've found. Then, each audio file is parsed, packed into an Example object, and written to a TFRecord file.
Even though the dataset is relatively large, an individual TFRecord file, storing one complete fold, is of a suitable size, around 550 MB. For larger datasets, you want to use more files. For such cases, the documentation has some tips.
Lastly, we implement the following main function to iterate over all folds:
To round off our small script, we define an argument parser. It takes the path to the audio directory mentioned at the beginning and the output directory. If this directory does not already exist, it will be created:
Running the script is done by calling python /path/to/script.py
With the script defined to create the TFRecord files, we probably want to read the files back later. So that's what we'll implement now.
Reading audio data from TFRecords
Once you've done it a couple of times, it's actually very straightforward to get the data out of the TFRecord files. We simply have to inverse the storing procedure. Previously, we put the features, named sr, len, y, and so on, into the box. We thus use the same names to get the data out.
The only caveat is the audio data. Because it is an array, we have to reshape it. That's why we stored the len property. Similarly, the filename has to be parsed to a string:
We use the following function to read the content of one or more TFRecord files. It returns a dataset object:
We can iterate over the first few elements using a for loop, inspecting them for any errors. Each sample consists of four components: The actual audio data, the label, the sampling rate, and the original filename:
One caveat is the uneven file duration. A regular batch operation would fail. Therefore, we have to pad the batches. We can do this in the following way:
That is it! Now it's up to you.
Summary
In this post, we parsed the UrbanSound8K dataset to TFRecord. To do so, we used the librosa python library and a couple of helper functions. Then, we iterated over the pre-defined folds and parsed each one separately.
In the end, we extracted the data and also covered padding a batch. This gave us a dataset we can iterate over.