A checklist to track your Machine Learning progress

Have you ever asked yourself where you currently are on your Machine Learning journey? And what’s there that you can still learn about?
This checklist helps you answer such questions. It provides an outline of the field, divided into three broad levels: Entry level (where everybody starts), intermediate level (where you quickly get to), and advanced level (where you stay for a long time). It does not list specific courses or software but focuses on the general concepts.
Let’s cover the levels in more detail, starting with the entry level.
Entry level

The entry-level is split into 5 categories:
- Data handling focuses on being able to work with small datasets
- Machine learning covers key concepts of classic Machine Learning
- Networks confines to DNNs, CNNs, and RNNs
- Theory intends to help you understand the ideas behind Machine Learning
- General lists the main things that you will work with at this stages
Data handling
This category focuses on enabling you to handle small datasets.
The most common data types are
- Images
- Audio
- Time-series
- Text
The datasets at this level are often already built-in with PyTorch or TensorFlow; no additional download is required. They are usually small both in size and complexity, and they generally fit into the memory. A good image example is the classic MNIST image dataset (PyTorch, TensorFlow), for the IMDB reviews dataset (PyTorch, TensorFlow) for text data, and small audio or time-series datasets.
Some beginner-friendly datasets require preprocessing — that's often no more than resizing images or shortening sentences. A few lines of code will easily do. Since the number of examples is either very low, or they are of small size only, you can do it during runtime (as opposed to running separate complex scripts in advance).
Since you are working with well-examined data, you’ll often find helpful guidelines, tips, and working solutions online.
To summarize this category: The focus is on handling small (built-in) datasets and applying simple preprocessing.
Machine learning
The classic approaches admittedly look dull compared to the might Deep Learning models. But be assured that someday you’ll encounter them too. A few concepts stand out:
Regression focuses on regressing data. Often you are given data points, and you have to infer unseen ones. These new points depend on the known (observable) points, and the regression aims to find this dependency.
Clustering contains many algorithms, which all do the same thing: Clustering similar data samples together and separating dissimilar ones. Many different approaches have emerged to solve this task, but I suggest checking out k-Means first.
And lastly, we have the Support-Vector Machine, one of the more sophisticated algorithms. SVMs try to construct a hyperplane that most suitably separates classes from each other. Read and use this approach once you’ve learned about the previous two.
To sum this up: While the focus of this checklist is on Deep Learning — as opposed to classic machine learning — it’s useful to learn the time-proven basics as well.
Networks
This category focuses on going from the previous classic ML towards neural networks.
Dense layers, and Dense Neural networks in general, are a good starting point. I guess that these layers are used veryfrequently and definitely in 90 % of the classification models. For example, in the most basic setting, you multiply the input by a weight and add a bias: w₁ × x₁ + b.
If you have two inputs, multiply each with its own weight and then add a bias: w₁ × x₁ + w₂ × x₂ + b.
If you have three, four, hundred inputs, the procedure remains the same — for a single neuron. If you have two receiving neurons and one input you have one weight and bias per neuron: w₁₁ and w₂₁, b₁ and b₂. If you have 20 inputs, you have twenty weights per receiving neuron and one bias per neuron. Don’t worry if that confuses you. After you have got your hands on this, it won’t be a problem.
The next network on the list is the Convolutional Neural Network, or CNN for short. CNNs use convolution operation, where a kernel goes over a matrix and calculates the inner product between itself and the patch covered. This way, you can extract small sets of features from the data and help the network detect such features regardless of the actual position. In other words: While the shoe on an image might be on the bottom, the network will be able to spot it also when it’s in the upper half. It’s hard to think about any successful research that has not used and benefited from this simple operation.
A third large class of networks are the Recurrent Neural Networks. These networks are useful when you have to retain information over a long time range. For example, consider this sentence: “The dog barks, and then he jumps”. To infer who “he” is, one must remember the beginning of the sentence “The dog”. RNNs and their derivatives help you model such temporal dependencies.
To sum this category up: You start with Dense neural networks, they are easy to understand and widely used. Afterwards, you work with CNNs to extract dispersed features and proceed to RNNs when temporal dependencies play a role.
Theory
This category focuses on theoretical concepts. It’s not only the math but also getting an intention about the techniques that enable ML in general and DL in particular.
To achieve this, it’s a good start to learn mathematical notation. Take the Σ, for example. Once you have worked with it for a while, you’ll begin to embrace its brevity. For example, rather than repeatedly writing, “We calculate the sum over all individual elements multiplied by the probability”, you can write:
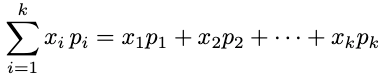
That’s way shorter and, over time, also more precise. Do we multiply the final sum? Or do we multiply each element? Using mathematical notation, this is clear.
Staying in the field of math, one thing to learn about is matrix operations. Remember the dense layers that I suggested as a good starting point? They can be written as a matrix operation; using the “bias trick”, you can also integrate the bias.
Learning about the classic machine learning techniques like regression and clustering also includes learning their background. This goes hand-in-hand: Once you learn about a new algorithm, you simultaneously learn the theory behind it. Ticking multiple items in one go is nice!
Once you go from classic to Deep Learning — that is, once you begin to use neural networks — you’ll encounter the convolution operation. At the entry level, this is the only technique that I propose to become familiar with.
When you begin to enhance your networks with such layers, you certainly want to measure the effect. This is where metrics come in, objective functions that quantify the success of your approach. Accuracy, mean squared error, recall and precision are the standard ones. Since the datasets are of little complexity, there is no need to switch to advanced metrics yet; you can keep that for later.
To summarise this category: You learn about reading mathematical notation, the (mathematical) ideas behind common techniques, and how to measure the success of your neural network.
General
This category contains techniques and best practices that you learn early on.
To work with neural networks, you want to use some helpful tools. These include an IDE (computer programs that help you write code) and GitHub (a service that versions your code).
If you are not familiar with a programming language, I suggest python as a beginner-friendly start. The number of resources for this particular language is HUGE. This is a critical point; as a beginner, you want to avoid building custom operations and consult the documentation to utilize built-in features.
These provided features also come in handy once you analyze your dataset. For example, what’s the value range? Are there some outliers? How extreme are they? Are there unusable data samples? These are some questions that you want to answer, which usually happens on the go:
You write a short code snippet — it breaks because a data sample is different — you update the code — you have learned more about your data.
Usually, the data you work with is supervised at this stage, which means it contains data → label mappings. For an image, this might be whether it's of a dog or a cat; for text, it might be positive or negative; for audio, it might be the music genre.
These mappings are part of the metadata, which is data about the actual data. This additional knowledge is often provided via CSV or JSON files. It’s, therefore, good to be able to parse them. Thankfully, the major programming languages provide code to achieve that; a few lines will do.
After successfully parsing the metadata and preparing the data with it, you also want to save the trained model to disk. Saving and loading models becomes important
- when you share your work with other learners,
- when you want to make your results verifiable,
- and when you simply want to persist them to disk and run inference later
If you have also done that, you should look at callbacks, code that gets executed during training. Want to save your model periodically? Want to cancel training early? These and other standard callbacks come shipped with large Deep Learning frameworks. You don’t have to write them from scratch. One, two lines of code is sufficient. Keep the complex callbacks for a later time.
In summary, this category focuses on general things that you’ll encounter early on, such as parsing metadata files, using IDEs, and analysing datasets.
Intermediate level

The intermediate level is where you’ll spend considerable time, and there’s much to explore here: Language models, large datasets, custom training loops, hyperparameter search, and many, many more. However, the transition from the previous level to this one is very smooth. I’d say that it takes three to four months, depending on your background, but: you’ll reach it faster than you think!
The things you learn are distributed over six large categories:
- Data handling brings large datasets and custom preprocessing into focus
- Custom projects wants you to gain experience with exactly that
- Networks contains several trends at this level
- Training covers much that comes with the previous two points
- Theory focuses on expanding your background knowledge
- General lists several items that you work with at this level
Data handling
Data handling focuses on larger and more complex datasets, extensive custom preprocessing, and efficient data loading.
I have observed that the datasets at this level tend to become bigger or more complex. Or both. Where you have previously dealt with small datasets that easily fit into RAM, you’ll now deal with 30 to 100 GBs of data. However, that should not scare you. Once you have consulted TensorFlow’s or PyTorch documentation, you will feel what to do.
This is also the case for imbalanced datasets, a second tendency at this stage. The labels — if it’s a classification problem after all — are no longer evenly distributed but rather concentrated on one large class. This goes hand in hand with more complex datasets, where the data can be of irregular shape.
A technique that you explore then is augmentation, artificially altering the existing data to produce new samples. You could apply this to a class with only a handful of samples. Or you can randomly rotate an image to make your network more robust.
Speaking of images, often, you’ll also have to normalize the data. For example, some images might be 400 × 400, but the majority is 350 × 350. That’s a case for rescaling, one possible technique. They are not restricted to image data, though. Other strategies exist for audio, text, and time-series data as well.
After you have normalized your data, you have to feed it to the network. Simply loading it into RAM is no longer possible, but writing a custom generator is. You don’t have to reinvent the wheel here; there are many resources out there helping you gain momentum.
Such generators can also be part of a custom pipeline: Preprocess the data in the generator before you feed it; no separate folder named preprocessed_data is required. Your pipelines might also help fellow students; why not share them?
In summary, this category focuses on large, complex, unbalanced datasets, which pose several challenges to overcome.
Custom projects
Custom projects are at the heart of the intermediate level. From my own experience, I vouch for the massive synergy effect that you get from doing them:
You start with a new dataset or even create one from scratch. To get this going, you have to write a custom pipeline (tick), handle large datasets (tick), and use advanced (tick) and custom layers (tick).
A custom dataset is not mandatory, however. Instead, you can use an existing one and try out new algorithms. Or you can participate in a (Kaggle) challenge and beat your competitors.
You see, with a few projects of your own, you will learn a tremendous amount of new things. And that’s what we are after.
In summary, this category might be short, but the list of things that follow from a custom project of yours is long.
Networks
At the intermediate level, the used networks become more advanced:
A first tendency is that networks get larger. The models from the previous stage usually are a few MBs in size, and a couple of layers will do. This will now turn to hundreds of MBs, with often more than 100, 200, 500 layers used.
A second tendency is that the standard layers are replaced by operations such as BatchNormalization, Pooling, and Attention. These are more sophisticated ones, and if you are missing a functionality: Now is the time to write a custom layer.
Speaking of more advanced features, generative networks and language models come into sight now. With your foundations set, you are now equipped to play around with them— if you can run them locally (looking at you, Transformers). Try switching to Colab and reserve a GPU or even a TPU if you need some more horsepower. There’s no need to rent a cloud computing instance just to play around. Do that once you have finalized your model and are ready to train some epochs.
As with other networks, code is often available. For example, Hugginface did an exceptional job with their transformers library, and TensorFlow has some tutorials on generative networks, too.
In summary, using more advanced networks and layers is interlinked with working on custom projects.
Training
The training category focuses on all stuff that goes together with training a model.
If we have limited resources, we may not be able to train a network completely — however, we can train parts of it. This technique is part of transfer learning:
We simply load a model pre-trained on a similar task and then fine-tune parts of it on our own dataset. You can, of course, also utilize a model from a completely different domain, such as image classification, to classify sound or text data. Since the classic pre-trained models come shipped with the major DL frameworks, you can rapidly switch between such networks.
The next point is custom embeddings. Embeddings are a smart way to compute and use the information stored within our data. An example:
A table and a chair are connected. This is reflected in the embedding of both words, which are just vectors of floats, of arbitrary size (often ~300). The similarity of the aforementioned words is worked into their vectors. This concept is not restricted to text data — though it is intuitive in that domain — but can be expanded to audio and image data as well.
Embeddings are mainly computed for single words. You can therefore download embeddings for the most common ones, such as “the”, “like”, “you”, “car”. The downside is that these might not reflect the knowledge in your data: The dataset they were pre-trained on might be about a car competition and thus features extensive relations between different types: truck, limousine, sports car. On the other hand, your own data does not focus on cars, so there’s too much unnecessary and too little useful information. In short, the pre-trained embeddings do not reflect the similarity between your data points. The solution is to train your own embeddings. This is actually done with the help of neural networks!
Once you have trained custom embeddings, you might be interested in custom callbacks, too. Cycling the learning rate? Possible. Terminating a model early? Possible. Extracting the output of intermediate layers during training? Again, possible but requires effort. When the standard callbacks don’t offer what you need, just implement your own.
The next points, data-parallelism and multi-GPU training, are strongly connected. Once you are lucky to use more than one GPU, or once your training takes ages, these concepts offer a remedy. Instead of using a single GPU to process your data, you utilize multiple. The input is shared across your devices, where each one runs the same model, and their weights are kept in sync.
Implementing things like this with more advanced models often requires you to write custom loops. On the downside, you have to write the training logic from scratch but are rewarded with insight and a lot of freedom in return. Guides on this are available from both PyTorch and TensorFlow.
The last two items are once again intertwined: TPUs are only available in the cloud, and both require some effort to get going. But they are fast: For a project one year ago, my group initially ran a model on a CPU for eight hours per epoch. Using GPUs brought the time to 15 minutes. After some hassle, I managed to run our code on TPUs, and we were rewarded with 15 seconds per epoch. That was fast.
From transfer learning to cloud TPU training, this category focuses on techniques that come with training advanced models, often to reduce training times or implement custom functionality.
Theory
This category gathers the concepts behind this level’s ideas.
Backpropagation is what runs it all; a clever technique to calculate the updates for your network, the gradients. Put simply, it’s the application of the chain rule, many times in a row. This is possible since your network can be considered as a (complex) chain of simple functions. These simple functions are your network's operations, and a layer’s activation function plays a critical role here.
Ever heard of ReLU? That’s such an activation function — using none at all (or only linear ones, e.g. y = x+2) would reduce your network to a linear classifier. (See the notes for more on this). There’s a whole world of research on this. Take the leaky ReLU, or LReLU, as an example:
The normal ReLU is y = max(x, 0). This would set the derivative to zero if your input were below 0. This means that every gradient that comes after in the backwards pass (that is, every layer that comes before) is zero, too. This is the reason for LReLUs: y = αx when x < 0, otherwise it’s y = x. That’s an easy fix for the above problem.
There are more functions to check out: GeLU, swish, SeLU, and so on. As long as you can derive it, you are fine.
The derivative is needed to calculate the gradients, as mentioned above. Once you have them, it’s the optimizer’s task to apply the updates. This is where the learning rate plays a role:
wᵘᵖᵈᵃᵗᵉᵈ = wᵒˡᵈ — learning rate × gradients
That’s the update rule for plain Gradient Descent, which goes inverse to the gradient. Other optimizers have their own update step, have a look at Adam or RMSProp for more.
Calculating the gradients in the first place requires a loss function. This function tells you how good your output is for a given input. The standard losses are cross-entropy, mean squared error, and so on, but there are more advanced ones for more advanced tasks.
This often goes together with more advanced metrics when accuracy alone won’t do it anymore. For imbalanced datasets, accuracy is not a meaningful metric; switch to macro F1 in this case. Tip: To compute any missing metric at a later point, save the network’s prediction and the ground truth.
Getting your hands on probabilities is a necessary step at this level. Let me talk from my own experience: It’s ok. After hearing about statistics and stochastics from many sources, the picture will get clearer. You might have used some methods already when calculating the average of your data or the normal data range. Have a look at Coursera to learn more, or browse through top-tier university lectures, which are frequently uploaded free of charge. (What a blessing, having access to high-quality material at no cost!).
Since we are dealing with advanced topics already, try to understand the advanced layers' concepts. Dropout is a good start, and BatchNorm is the next candidate.
The same holds for learning about regularization. In general, these are techniques to reduce the training error without affecting the test results. In other words: Make your network do good on the training data without making it do bad on the separate test data.
The last point in the theory category is a rather vague one: Knowing common problems. I intend to make you gain a wide knowledge of everything that comes together with deep neural networks. That includes such phenomenons as vanishing gradient, mode collapse, and overfitting. You might encounter some of them on your journey, and then it’s advantageous to know what’s going on. Ultimately, this helps you solve problems and lets you avoid them the next time.
In summary, this category covers associated topics that solidify your understanding of Machine Learning.
General
This broad category covers miscellaneous topics that you’ll encounter at this level.
Coming from supervised data — data where (human) annotations are available — , you now extend to unsupervised data. This is the case when you work with generative techniques. You can also combine the best of both worlds: Train an AutoEncoder to generate realistic images and use the learned weights in another classifier network. This is then some kind of (advanced) transfer learning.
Working with any data, whether supervised or not, often requires you to split the data into a train set (also development or dev set), a validation set, and a test set. It’s easy to split the data into three portions, but you’ll usually want stratified splits, where the class percentages remain approximately similar in all splits. For example, when you have hundred data points and 50 for classes A and B, you want to retain this ratio in all three splits.
To later trace back anything that you did, not only when splitting datasets, it’s a good practice to version your code. You won’t need to maintain 100 folders. It’s easier and more comfortable to work with tools that help you: Git is the first place.
This goes together with tracking your experiments. Tracking can include storing the model but basically means saving any metrics and settings. For some runs I did months ago, I recently had to check the average run time. I’d have been hamstrung had I not used tools like Weights&Biases to save the experiment data. With that, it was fairly easy to get the needed information.
The same holds for model configurations: To replicate runs or papers, you want to know the number of filters per layer, the kernel size, the dropout probability, and so on. Tracking your experiments is therefore becoming a mandatory thing. Not only does it objectively tell which runs did best, but it’s also cool to see those graphs populate:
Taking experiment tracking one step further, you can also do a hyperparameter search. To determine the best values, you start multiple runs in parallel. Each run uses a different set of parameter values, and a central coordinator decides which ones lead to a better score. This is a time- and compute-intensive process and requires some initial setup. But once you have done one search, you are well equipped for the next time.
Having spent much time determining the best metrics, the best parameters, the best optimizers, you don’t want to let the final model get dusty. Instead, use some tools like streamlit.io for prototyping an application quickly and then using your cloud skills to deploy your model. Finally, document the code and publish your findings on GitHub. People like me will thank you for that!
Having seen so much and trained many models, you certainly have gained some experience in problem thinking. I am not sure if that’s a thing, but it simply means to know what to do when xyz happens. This might be simplifying the problem, asking questions on StackOverflow, or consulting other folks. This is an essential part of our learning process: Even though two problems might be completely different, there’s always something that we have learned from a third problem earlier that we can use now.
This is a helpful skill both for your work and for contributing to other projects: Large packages like Hugginface and PyTorch rely on the community’s feedback to grow. Use what you have learned to collaborate.
Lastly, with all this in mind, know that this is an ever ongoing process. It’s part of the research landscape to propose new findings and falsify old ones. Reading papers is a good way to stay in touch with this progress and is never truly completed.
Start with the abstract. This part is often submitted before the actual paper, so authors spend some time here. It summarizes the story of a paper. Jump to the conclusion afterwards. If you think that this paper is something for you, then you can read it entirely. For those papers that received large media coverage, smart people might already have written a blog post about it, explaining it in their way. It won’t hurt to check them out.
In summary, this category covers a broad range of topics on your machine learning progress: From creating data splits to reading papers, there’s much going on here.
Advanced level

Compared to the intermediate level, this one looks short. That’s a trap! This field is large. Everything that you have learned so far plays a role here, too. Optimizers? Invent your own ones. Custom training loops? Now create a completely new algorithm. Contributed to projects? Publish your own in papers.
All the following categories extend the concepts from the previous level:
- Data handling now focuses on huge, multi-modal datasets
- Custom projects now features generative techniques
- Training builds on the previous one by becoming more sophisticated
- Theory expands to completely new fields
- General extends to a wider range of topics
Data handling
This category goes one step further than its counterpart in the intermediate level and shifts to even larger datasets.
The adjective huge is a relatively vague description of the dataset size. In terms of GB, this is more than 100, 200 GBs. In terms of epoch time, this is more than an hour per single pass. This depends on your available compute power — your knowledge of multi-GPU or TPU training comes in handy. You can apply to the TPU research cloud to speed up your training.
The speed-up can also be achieved by running distributed pipelines. For dataset pre-processing, Apache Beam is such a framework; for TensorFlow, I know that you can also distribute the data pre-processing (not the training but the actual pre-processing). You certainly want to work with a Kubernetes cluster or similar here. The large cloud providers (AWS, GCP, Azure) offer relevant solutions.
These distributed pipelines are of use when working with multi-model datasets. It’s no longer a single data type that you work with but a combination of many. A simple example would be text and images together, where the text describes the image’s content. Storing and parsing such data can be a hassle; you might want to write a custom generator to make things easier.
In summary, this category extends to larger and more complex datasets.
Custom projects
This category only contains a single item:
Working on custom generative projects. The field of GANs has become quite large: BGAN, GAN, *GAN, CycleGAN, … Pick one and work with a custom dataset. So many things from the previous level come together here: Regularization, advanced losses, probabilities, custom layers. It’s thus a great opportunity to put into action what you’ve learned.
Training
The training category now focuses on speeding up training.
As the datasets get bigger, the training times get longer. The first method is to use mixed-precision training. Rather than using 32-bit precision, the model tries to use 16-bit precision. To ensure numerical stability (rounding errors, etc.), parts of the weights remain in their original type, and 16-bit precision computation is used where possible. Recent GPUs have special hardware that accelerates computation in float16 format; the training can often speed up 2 to 3 times.
The second method to lower training times is to expand from multi-GPU to multi-worker training. The devices are no longer installed in a single node but distributed across many. If you can install them all in one place, do this, as there is a communication overhead when running multi-worker setups. However, this is often limited to 8 or 16 GPUs per node, and if that’s not sufficient, you can still scale computation by splitting the training load over multiple workers with multiple GPUs each.
Of course, if you have access to multiple TPUs, then training time will go down, too. This then uses TPU pods; Google has extensive documentation here. There is something magical about going from 8 TPU cores to 2048. You definitely want to make sure that your code is efficient, as compute-time is money.
The last step is primarily tailored to larger-than-RAM models: model-parallel training. In this setup, the model is no longer replicated on the specific devices but placed over all of them. Thus, for example, one set of layers might be processed by GPUs 0 to 4, the next set by 4 to 8, and so on. This is also a technique to resort to when a layers activation is larger than the available RAM.
In summary, training focuses on speed. Running things faster is better.
Theory
The theory part introduces a few completely new domains in the wide field of Machine Learning, starting with Graph Neural Networks.
Graphs can model many data interactions. Think about a map, where the vertices are places of special interest, and the edges are connections between them. Such a structure is also present in molecules and social networks. Graph Neural Networks use techniques from DL to use this graph-stored data. There is a large ongoing field of research.
The same is true for open-endedness. This is by far the most interesting point on the whole list. Think about Nature, about the birds that frequently pass by your window. They did not always look that way. And they also won’t remain that way forever. Evolution is at work here, though this wording is too weak. Evolution is not a process; it’s something at work that invented all. You, me, computers, birds, fish, trees. And it’s by no means finished. Evolution is thus an algorithm that never terminates (the halting problem, anybody?). One hope of AI is to achieve something similar, to create new things. Much like we humans do.
A short first reach into that direction is Evolutionary Algorithms, which create something. But only a small amount. And compared to Nature/Evolution, that’s like nothing. The same holds for many things that we daily do. Thousand push-ups? Sure, but Nature created birds, plants, dogs, cats, trees — try to match that. A handstand? Alrighty, but Nature created fish, cows, pigs, flowers, bacteria — match that. There’s much that we have achieved, but there’s much to learn (and invent). Have a look at this article to learn more about this fascinating topic.
A more accessible domain is that of Reinforcement Learning. I have placed it in the advanced level to not scare beginners. Would I have seen all the concepts of RL in my early days (in fact, I did), I would have doubted if I can even grasp this all. The concepts are not hard, but simply too much for beginner-to-intermediates. Once you have a solid foundation, you are ready to check out RL.
The last point in the theory category is to expand your knowledge beyond computer science. It’s always beneficial to know much, and biology and chemistry and psychology and physics and … are great fields to get your hands on. Not that you have to do a complete study, it’s more that one or two courses in those fields are ample enough.
Biology is a great example for our research: GPT-x with billions of connections, Turing NLG and Megatron LM, and Switch Transformer with an astonishing one trillion parameters. And they only can do one or two things. While we as humans, with no way to plug in additional hardware or to crunch through TBs of data in minutes, can do so much more. Walking and solving math at the same time? Gotcha. Swimming and replaying an interview? Gotcha. Writing a paper and eating snacks? Gotcha.
Running your heart while you sleep, eat, walk, swim, shower, cry, laugh, jump, fall, dive, climb, drive, wonder, learn, write, compose, create, dream, think? Does not even require our attention.
Compared to what a single and a group of humans can do, these models fall short. And this is where biology, chemistry, physics and other fields can help us advance the state-of-the-art.
In summary, you extend from standard DL tasks to those grand ones.
General
This category lists general patterns that emerge at the advanced level.
Efficient code: that’s important early on, obviously, but when your train your 500 million parameter model on three servers with 128 GPUs over 5 days, you really want to make sure that your code is fast. This is not a one-person project anymore, but a group effort. Having a look at the Transformers paper tells us that it’s the combined work of many people that gets things going.
From efficient code to Quantum Deep Learning, it’s quite a stretch, admittedly. But at this level, you have already learned too much to not have a look at this field. It’s listed in General rather than Theory since it’s a strongly disjunct field. Biology can foster the development of algorithms, but quantum physics is a completely separate domain. Once again, the main motivation is to do things, fast. Trying a combination of passwords in a sequence is tedious. Trying a thousand of them simultaneously is fast. We do not even have to look far; from migratory birds, we currently assume that they use quantum effects to feel the earth’s magnetic field. Nature is at it, once again.
If you don’t have it done already, implementing papers is a good practice: You learn something new, solidify your coding skills, and even earn money.
Speaking of papers, now it’s the time to go from reading papers to also understanding (most of) them. You’ll naturally focus on a few domains and try to grasp things there. This is part of staying up-to-date. There’s too much going on in the field of AI research:
One year ago, I had a lecture on NLP with ML. We had some charts on the model size, and Megatron LM was listed as one of the largest models. Then, shortly after the lecture, GPT-3 emerged, blasting the scale. And this is only one domain. There are GANs, Audio models, Image classifiers, and many, many more. So it comes down to having a general overview, provided by newsletters such as Andrew Ng’s The Batch, and then focusing on your own domain.
That’s research, then. Like the previous two points, this is never quite done.
In summary, you need efficient code and want to stay up-to-date.
Where to go next?
You can find the checklist on GitHub here and Notion here. Copy and customize it, then gradually tick it.
If you are looking for specific resources:
- Most of the entry-level is covered by deeplearning.ai’s TensorFlow Developer Professional Certificate
- Parts of the entry and intermediate and advanced levels are covered by Berkley’s Full Stack Deep Learning course
- Some parts of the intermediate and advanced levels are covered by DeepMind’s Advanced Deep Learning & Reinforcement Learning lecture
- Parts of the intermediate and advanced levels are covered by deeplearning.ai’s TensorFlow: Data and Deployment Specialization and TensorFlow: Advanced Techniques Specialization
If you are looking for a more concrete list, you can check Daniel Bourke’s roadmap here.
Further notes
- This checklist is biased by my own experience.
- RNNs can be used for any kind of data. Vanishing gradients and long periods make them more difficult to train, however.
- There is not that much difference between PyTorch or TensorFlow. As a beginner, there’s no pressure to pick one over the other. However, once you have more progress, you might encounter a problem and notice that it might be easier in the other framework. That is quite common, but let me say this:
The fact that you encounter such problems means that you are deep inside the material; switching the framework would thus incur the massive overhead of starting anew. It’s, therefore, often better to bite the bullet and crunch through it. (I had a similar experience when I was writing a custom layer in TensorFlow. What an effort it was, back then!). - Embeddings are not limited to single data points. You can compute embeddings for complete sentences, for example. Further, a pre-out dense layer is often used as an embedding too.
- Embeddings are just arrays of floats: [0.1213, 0.542, 1.993, …], and you can often inspect them.
- I noted that using no activation functions can make your network reproducible to a single linear classifier. This is correct for dense-only neural networks. The problem with this is that you can only learn linear dependencies, which is generally not what you want.
- Generative techniques can be extended to work with supervised data, which is what, e.g., the CycleGAN does: You translate between two known domains, thus requiring labelled data per domain. The initial generative techniques, the original GAN and AEs and VAEs, do no rely on such labels, though.
- I have missed some things, for sure. Please leave comments and let me know.
- You don’t have to go to university courses to learn all this. The internet has democratized the transfer of knowledge, so just have a look at YouTube, Google’s blog, OpenAI’s blog, DeepMind’s blog, and the forth.